


OpenAI GPT-5.2 Codex vs. Gemini 3 Pro vs Opus 4.5: Coding comparison
.webp)
For a few weeks now, the tech community has been amazed by all these new AI models coming out every few days. 🥴
But the catch is, there are so many of them right now that we devs aren't really sure which AI model to use when it comes to working with code, especially as your daily driver.
Just a few weeks ago, Anthropic released Opus 4.5, Google released Gemini 3, and OpenAI released GPT-5.2 (Codex), all of which claim at some point to be the "so-called" best for coding.
But now the question arises: how much better or worse is each of them when compared to real-world scenarios?
TL;DR
If you want a quick take, here is how the three models performed in these tests:
- Gemini 3 Pro: Best overall for UI. It nailed the Figma clone and even built the best “Minecraft” by going 3D, but completely bombed the LeetCode Hard (failed right away).
- GPT-5.2 Codex: Most consistent all-rounder. Solid Pygame Minecraft, a decent Figma clone, and a correct LeetCode solution that still hits TLE on bigger cases, but it’s still great considering the pricing.
- Claude Opus 4.5: Worst performance. UI work was a mess (Pygame + Figma), and the LeetCode solution also ended up with TLE.
If your day-to-day is mostly frontend/UI, Gemini 3 Pro is the clear winner from this test. If you want something steady for general coding, GPT-5.2 Codex is the safer pick. This might sound controversial, but in our test, which was mostly frontend, Opus 4.5 just didn’t justify the pricing overall.
⚠️ NOTE: Don’t treat these results as a hard rule. This is just a small set of real dev tasks that shows where each model holds up.
Model Specs and Pricing
💁 If you already know the context windows, benchmarks, and pricing, feel free to skip to the actual tests below.
Claude Opus 4.5 (Anthropic)
Opus 4.5 is Anthropic’s “premium” coding and agent model, and it ships with a 200K context window.
Anthropic reports 80.9% in the SWE-bench Verified, which is right up there in the list with the best coding models.
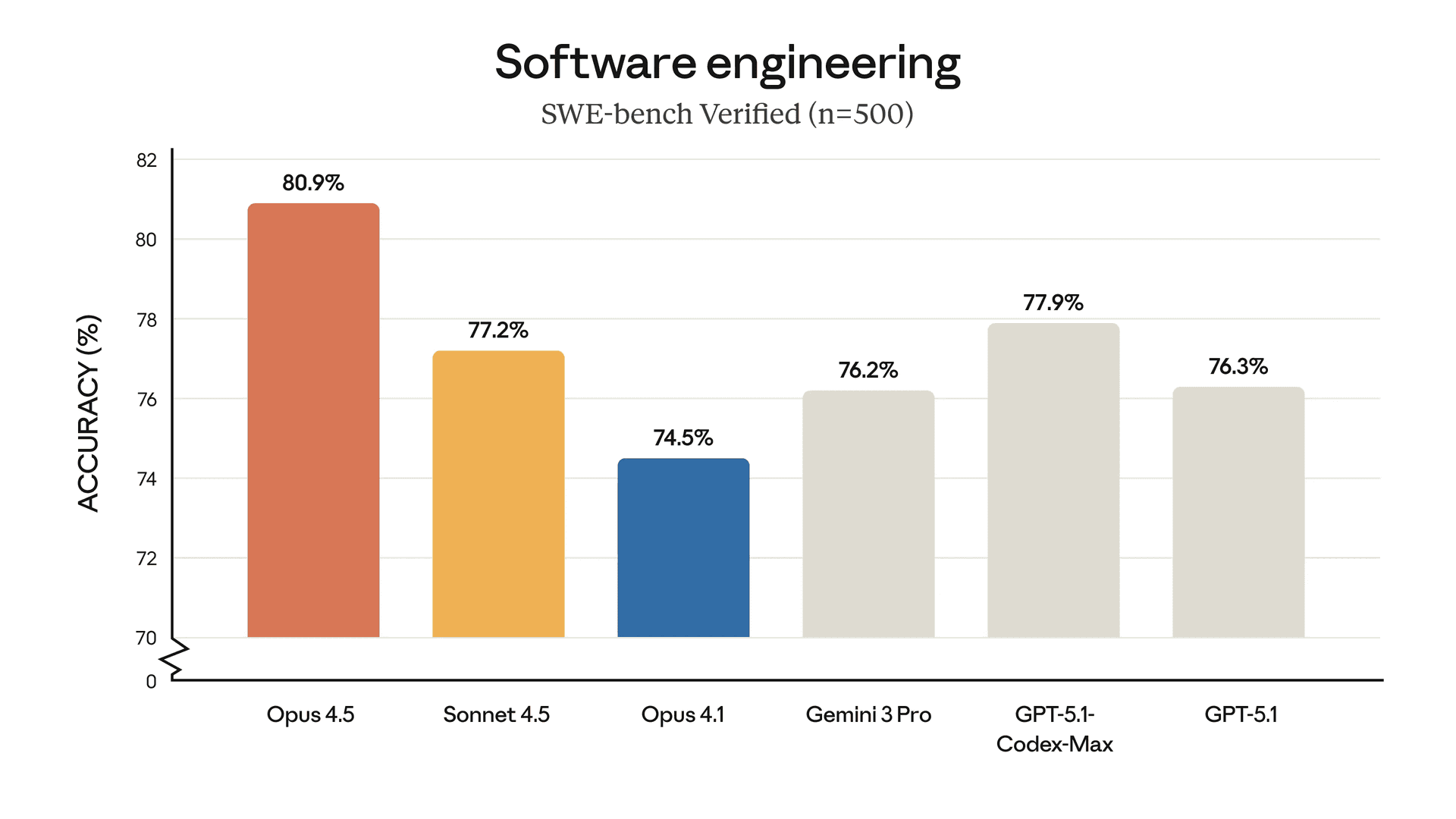
There are definitely a lot more benchmarks that count. To learn more on the model stats, visit the model announcement.
Pricing starts at $5/M input tokens and $25/M output tokens, with prompt caching discounts available.
Gemini 3 Pro (Google)
Gemini 3 Pro is the Google's flagship model and it's biggest advantage is having 1M token context window with 64K output which is huge compared to the other two models.
For coding benchmarks, Google lists 76.2% on SWE-bench Verified (single attempt) and strong agentic coding results on Terminal-Bench 2.0.
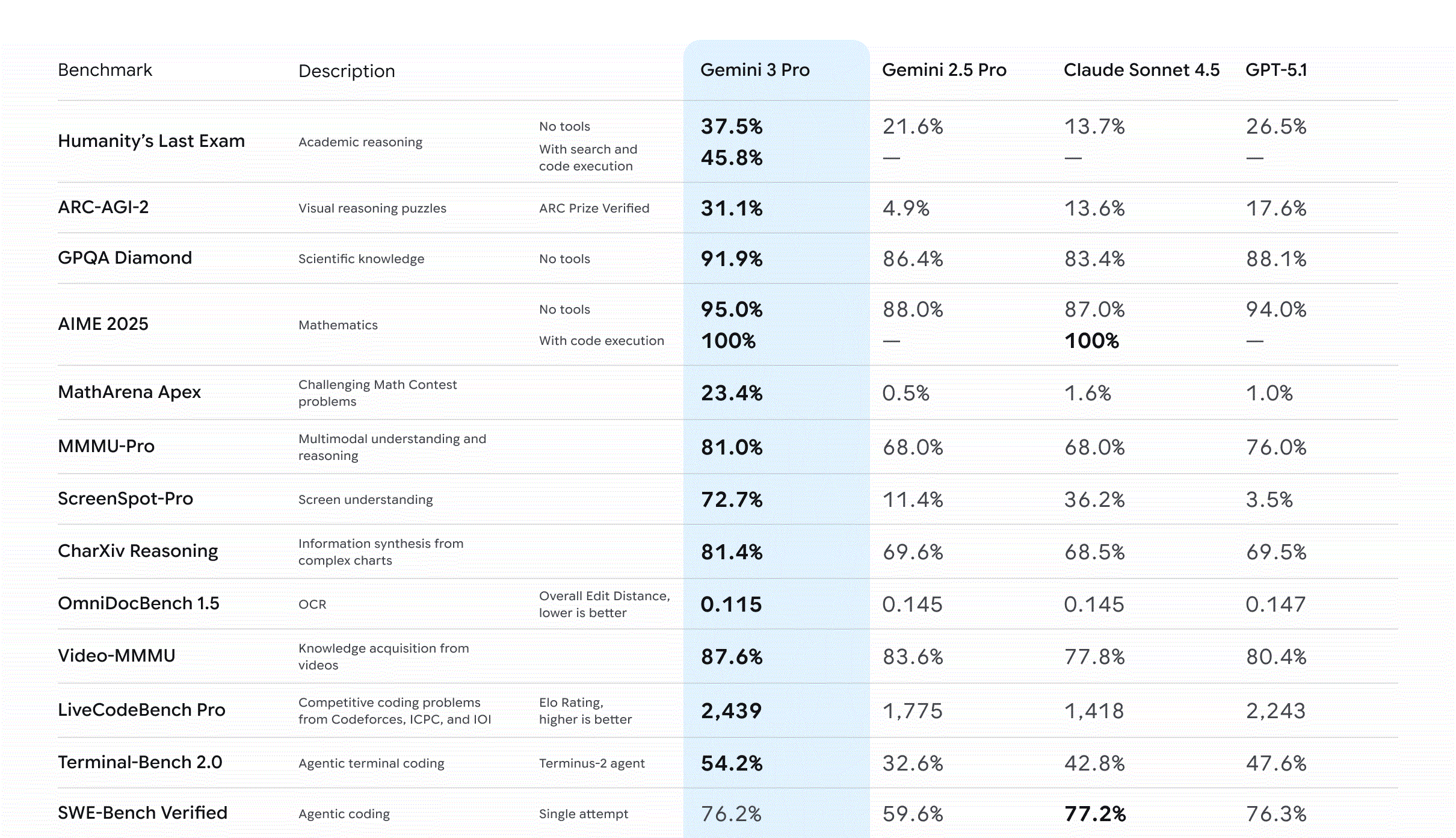
For pricing, the preview model is listed at $2/M input and $12/M output for prompts up to 200K tokens (higher if you go past that).
GPT-5.2 Codex (OpenAI)
GPT-5.2-Codex is OpenAI’s GPT-5.2 line tuned specifically for agentic and overall coding inside Codex. It is available as part of paid ChatGPT plans (Plus, Pro, Business, Edu, Enterprise).
On paper, it’s strong. OpenAI reports 80% on SWE-bench Verified for GPT-5.2 Thinking, and says GPT-5.2-Codex hits state-of-the-art on SWE-Bench Pro

For pricing, OpenAI does not currently show a separate per-token row for gpt-5.2-codex on the API pricing table, so the safest thing to assume the GPT-5.2 API pricing itself: $1.75/M input, $0.175/M cached input, and $14/M output.
GPT-5.2 itself has a 400K context window with up to 128K output tokens, which is a big deal for long coding tasks.
Real-world Coding Tests
💁 Personally, though, I have really high hopes for the Opus 4.5, as that's something I've found everybody seems to be using recently. Let's see if we can spot any major differences in code between Opus and the other two models.
Let's start with something interesting:
1. Build simple Minecraft using Pygame
The task is simple: all three LLMs are asked to build a simple Minecraft game using Pygame.
This is mainly to see how good they are at creating UI and handling things a bit differently than using something like JavaScript, which everybody is already testing.
💁 Prompt: Build me a very simple minecraft game using Pygame in Python. Make it visually appealing and most importantly functional.
GPT-5.2 Codex
Here's the response from GPT-5.2 Codex:
You can find the entire code it generated here: Source Code
This one turned out to be much better than I thought. The character movement works, and you can do some basic "Minecraft" things without any errors. There are even different types of blocks implemented, and you can cycle through them using the numbers 1-9. It even shows the FPS it is running on.
It took about 5 minutes to implement. The total token usage is 42,646, with 31,704 input tokens and 10,942 output tokens.

Spoiler Alert: This response turned out to be much better and more functional than our best coding model, Claude Opus 4.5. 🤷♂️
Gemini 3 Pro
Here's the response from Claude Opus 4.5:
You can find the entire code it generated here: Source Code
This one was easily the best out of all three models.
Instead of forcing a flat 2D Minecraft clone, Gemini took the right approach and implemented it in 3D, which makes it feel way closer to the real thing. Movement feels solid, the overall look and feel is noticeably more polished, and the result comes across as an actual playable mini-game rather than a rough prototype.
It also did this pretty efficiently: it used 11,006 tokens total, with 112 input tokens and 10,894 output tokens, and the estimated cost came out to about $0.13.
Claude Opus 4.5
Here's the response from Claude Opus 4.5:
You can find the entire code it generated here: Source Code
For the first test, I was straight-up disappointed. There are things that it has implemented, but when you launch the program, it rotates the game screen, and then you can do nothing.
None of the controls work, the CPU usage goes way up, not sure why that is the case, and finally, it crashes the entire program and exits.
Since none of it works, the time spent implementing it doesn't matter. But if you're curious, it took about 4 minutes and 15 seconds, and the cost was $0.86. The output token usage was about 11.4K.
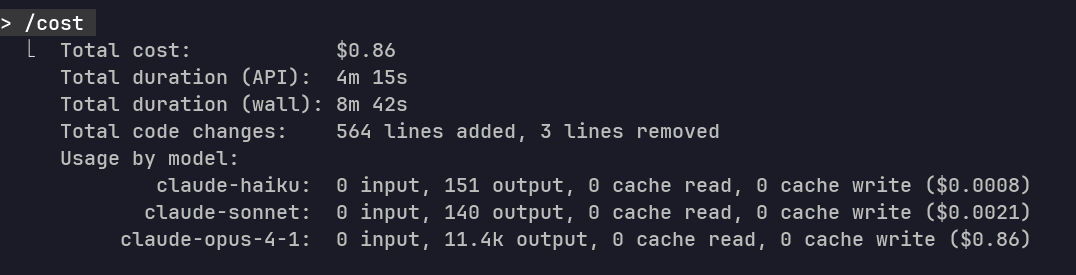
You can find the raw response from Claude Opus 4.5 here: Raw Chat Response
A complete waste of a dollar if I have to say it. 😕
2. Clone a Figma Design
Now, let's spice things up a little.
For this test, we'll be comparing all three of the models on one Figma file giving them access to the Figma MCP server.
💁 Prompt: Clone this Figma design from the attached Figma frame link. Write clean, maintainable, and responsive code that closely matches the design. Keep components simple, reusable, and production-ready.
You can find the Figma design template here: Figma Dashboard Template
GPT-5.2 Codex
Here's the response from GPT-5.2 Codex:
You can find the entire code it generated here: Source Code
This turned out great and much better than I expected, and it is obviously miles better than what Opus 4.5 produced for the same Figma frame. The overall structure is there, the grid is mostly right, and it actually looks like a dashboard instead of a random layout.
That said, it still falls short compared to Gemini 3 Pro. The clone is a bit more “flat”, some spacing and sizing feels off, and a few details don’t match the design.
The pricing came out roughly $0.53 with about 35K output tokens.
Gemini 3 Pro
Here's the response from Gemini 3 Pro:
You can find the entire code it generated here: Source Code
This response is absolutely awesome, and honestly, it is what I would prefer over anything else in this test. The layout feels right, the spacing is clean, the font matches the one in the Figma dashboard, and it actually looks like a real dashboard you would ship.
A couple of icons and images don’t look exactly right, but that’s not a big fix. Swap the assets, tweak a few sizes, and you’re basically there.
The total cost for this run took $0.35 with roughly 29k output tokens.
Claude Opus 4.5
Here's the response from Claude Opus 4.5:
You can find the entire code it generated here: Source Code
Honestly, the UI it produced is trash. It could not get the layout to work, and what it renders looks nothing like the Figma frame. A bunch of spacing and structure is just wrong, and even worse, half the text on the page doesn’t match what’s in the design. It feels like a random dashboard mockup, not a Figma clone.
On cost and timing, this run took 7m 6s of API time. Opus generated about 17.3k output tokens, costing roughly $1.30.

Complete nonsense. I'm starting to feel Opus 4.5 is even worse with UI than Sonnet 4.5. Sonnet 4.5 is pretty good, though.
3. LeetCode Problem (Hard)
For this one, let’s do a quick LeetCode check with a super hard LeetCode question to see how these models handle solving a tricky LeetCode question with an acceptance rate of just 10.6%:
Maximize Cyclic Partition Score.
GPT-5.2 Codex
You can find the entire code it generated here: Source Code
The code GPT-5.2 Codex wrote works and provides a correct solution, and its clearly better than Gemini 3 Pro on this problem. But like Opus 4.5, it still is not optimized enough for a Hard submission. On certain larger inputs, it hits TLE (time limit exceeded), so the submission fails on LeetCode.
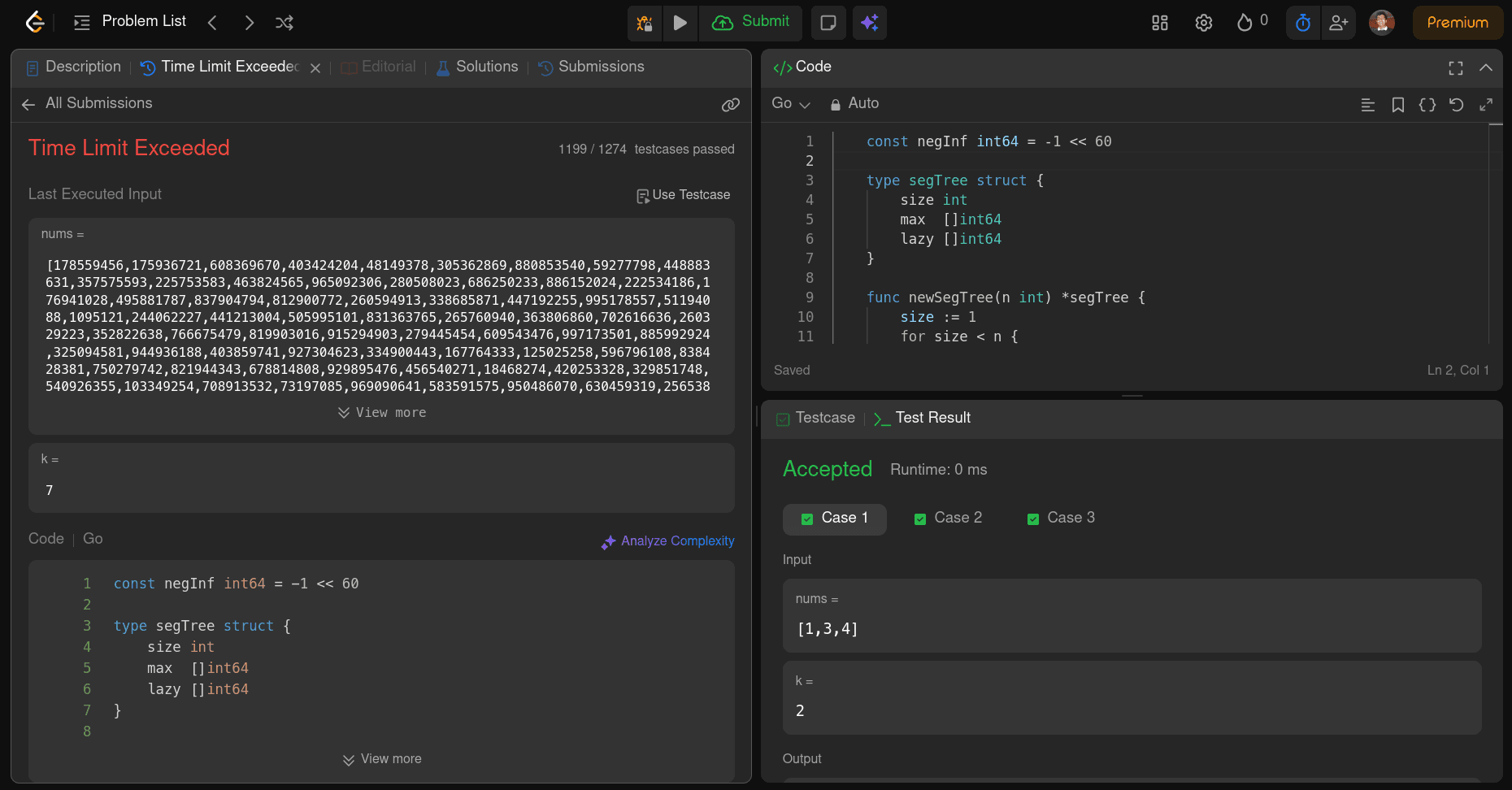
On token usage, this run used 544,741 tokens total, with 478,673 input tokens, and 66,068 output tokens (the “reasoning 57,088” is part of that output count). The estimated cost comes out to about $1.97 total (roughly $0.8377 for input, $0.2087 for cached input, and $0.9250 for output).

Gemini 3 Pro
You can find the entire code it generated here: Source Code
Got it. Here’s a rewrite in the same style, but reflecting that it fails immediately:
The code Gemini 3 Pro wrote doesn’t hold up in practice. It fails right away and does not even pass the first three test cases, so it is not just an optimization issue or a TLE problem. This one is simply completely incorrect.
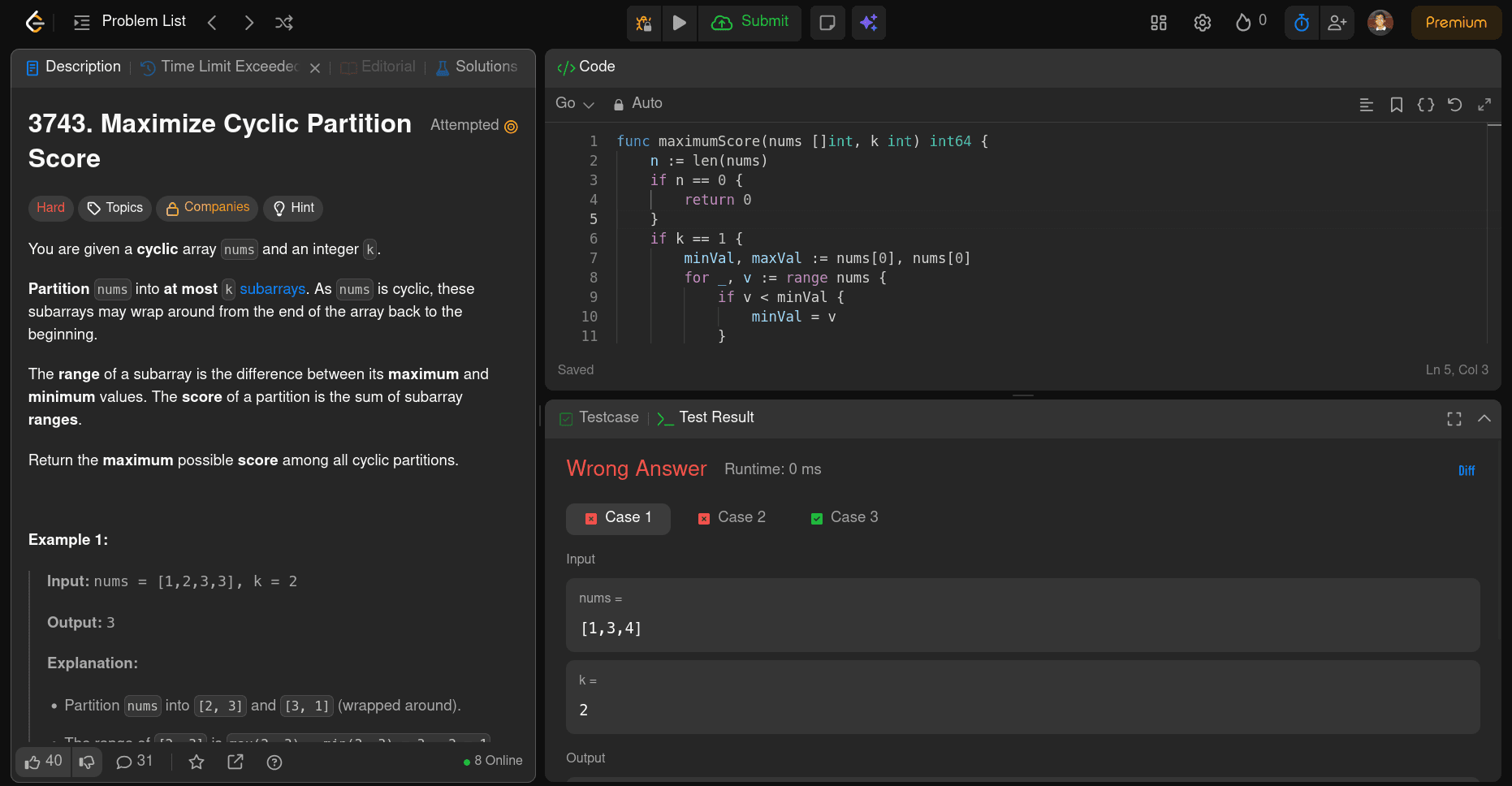
On cost and usage, it used 5,706 tokens total, with 558 input tokens and 5,148 output tokens, and the estimated cost came out to about $0.062892 (roughly $0.001116 for input and $0.061776 for output).
Claude Opus 4.5
You can find the entire code it generated here: Source Code
The code it wrote works and produces the right results on smaller tests, but it is not optimized enough for a hard problem. On certain larger inputs, it hits TLE (time limit exceeded), so the submission fails on LeetCode.
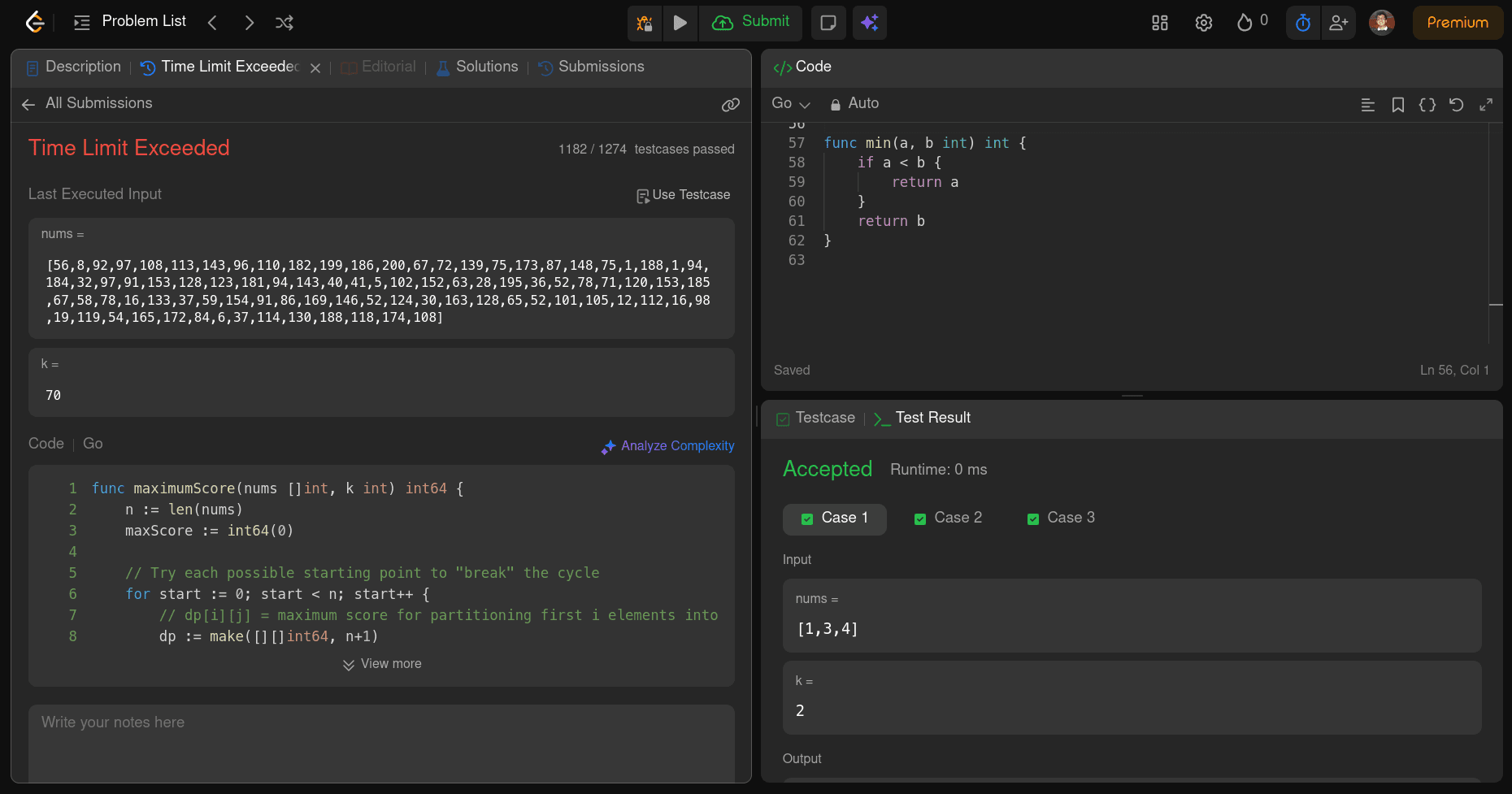
Regarding the cost and timing, this run took 2m 36s, and the Opus model generated about 5.9k output tokens, costing roughly $0.47 for Opus.

Conclusion
It's fair to say that the model Opus 4.5 didn't really turn out to be the best in our test, at least not really in frontend. Do let me know if you want a quick agentic test for these models in the comments.
Now is not the time to wait for luck. Imagine there are so many different AI models that can build stuff like this in no time with this great accuracy. So, other than the models' benchmark takeaway, consider the fact that you need to start building stuff, improve your coding skills, and rise above being a junior engineer, or get ready to be replaced by AI (probably 🤷♂️).
However, this doesn't mean these models are the solution to everything. There will be times when even better models will appear and beat all these models' benchmarks.
This is never-ending, and even the hype about achieving AGI is starting to sound real.
What are your thoughts on these models? Let me know in the comments! 👇


Get server-less runtime for agents and data ingestion

Tensorlake is the Agentic Compute Runtime the durable serverless platform that runs Agents at scale.
“With Tensorlake, we've been able to handle complex document parsing and data formats that many other providers don't support natively, at a throughput that significantly improves our application's UX. Beyond the technology, the team's responsiveness stands out, they quickly iterate on our feedback and continuously expand the model's capabilities.”
"At SIXT, we're building AI-powered experiences for millions of customers while managing the complexity of enterprise-scale data. TensorLake gives us the foundation we need—reliable document ingestion that runs securely in our VPC to power our generative AI initiatives."
“Tensorlake enabled us to avoid building and operating an in-house OCR pipeline by providing a robust, scalable OCR and document ingestion layer with excellent accuracy and feature coverage. Ongoing improvements to the platform, combined with strong technical support, make it a dependable foundation for our scientific document workflows.”
"For BindHQ customers, the integration with Tensorlake represents a shift from manual data handling to intelligent automation, helping insurance businesses operate with greater precision, and responsiveness across a variety of transactions"
“Tensorlake let us ship faster and stay reliable from day one. Complex stateful AI workloads that used to require serious infra engineering are now just long-running functions. As we scale, that means we can stay lean—building product, not managing infrastructure.”
