


The End of Database-Backed Workflow Engines: Building GraphRAG on Object Storage

GraphRAG sounds elegant in theory: build a knowledge graph from your documents, traverse it intelligently, and get better answers than vanilla RAG.
Then you look at the compute requirements.
To build a GraphRAG system, you need to: parse documents, chunk text, generate embeddings for every chunk, extract concepts from every chunk, compute pairwise similarities, build graph edges, and store everything in a queryable format. For a single 100-page PDF, that’s thousands of API calls, millions of similarity computations, and hours of processing.
Now imagine doing this for 10,000 documents. Or 100,00
What GraphRAG Actually Needs from Infrastructure
The algorithm is straightforward: chunk, embed, extract concepts, build edges, traverse. The infrastructure requirements are not.
Parallel execution
Documents are independent. Processing them sequentially wastes time. You need a system that can spin up workers on demand and distribute work across them.
Heterogeneous compute
PDF parsing needs memory. Embedding generation is I/O-bound waiting on API calls. Concept extraction needs CPU for NLP models. Running all of these on the same machine means over-provisioning for the hungriest step.
Durable execution
A 10-hour ingestion job will fail somewhere. Network timeout. Rate limit. OOM. When step 3 fails, it needs to read step 2’s output from somewhere durable. Without checkpointing, you start over from zero.
Job orchestration
You need something that spins up workers, tracks dependencies, retries failures, aggregates partial results, and decides whether to proceed or abort.
The DIY Stack
Building this yourself means assembling:
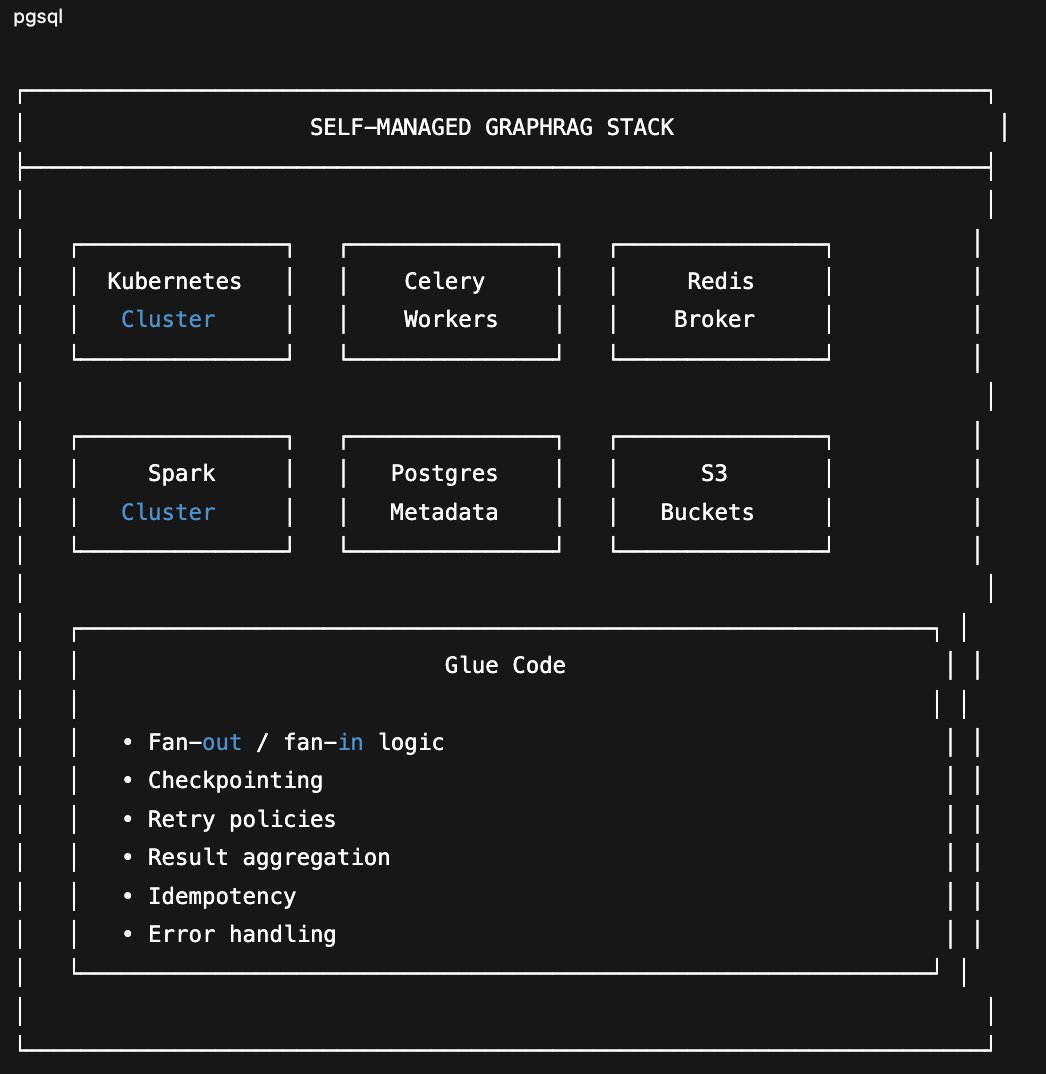
Kubernetes
Kubernetes is used for container orchestration. But Kubernetes doesn’t know anything about your jobs. It manages containers, not computations. It won’t schedule your tasks, track dependencies, or handle fan-out.
Celery + Redis
Celery and Redis are typically used for task queuing. Note: queuing, not parallel execution. Celery distributes tasks to workers, but it is fundamentally a message broker with worker processes attached. It doesn’t understand data locality, can’t optimize task placement, and treats every task as independent. When you need real parallelism, map-reduce over ten thousand chunks, aggregating partial results, handling stragglers, Celery gets you partway there. For the rest, you end up writing glue code or reaching for Spark.
Spark
Spark is brought in for actual parallel compute. Now you are running a third system. Spark knows how to partition data, schedule parallel tasks, and aggregate results. But Spark wants to own the entire pipeline. Mixing Spark jobs with Celery tasks means shuffling data between systems, managing two job lifecycles, and debugging failures that span both.
Postgres
Postgres is used for job metadata and durability. This is the state that workflow engines like Airflow and Temporal manage except now you are building it yourself.
The glue code
You have a container orchestrator that doesn’t understand jobs, a task queue that doesn’t understand parallelism, and a compute engine that doesn’t integrate cleanly with either. You end up writing hundreds of lines to bridge these systems, and every bridge is a place where failures hide.
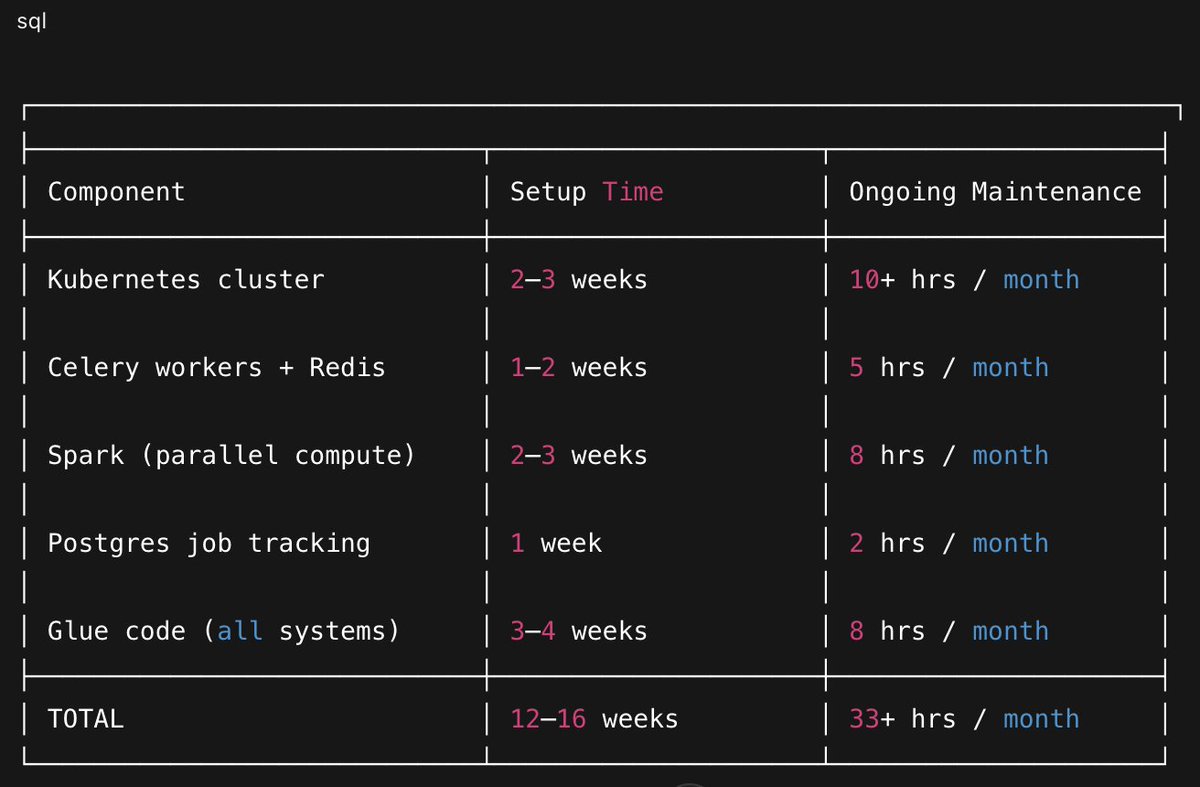
And this assumes you get it right the first time. You won't.
Kubernetes was built for orchestrating long-running microservices, not bursty batch jobs. The Cluster Autoscaler checks for unschedulable pods every 10 seconds, then provisions nodes that take 30-60 seconds to come online. For a GraphRAG pipeline that needs to fan out to 500 workers immediately, that's minutes of latency before work even starts. The autoscaler [prioritizes stability over speed](https://scaleops.com/blog/kubernetes-cluster-autoscaler-best-practices-limitations-alternatives/) a reasonable tradeoff for web services, but painful for batch processing.
This is why most GraphRAG implementations stay as notebooks. The infrastructure tax is too high.
A Different Approach: Object-Store-Native Compute
For the past two years, we've been quietly building a new serverless compute stack for AI workloads at Tensorlake(https://tensorlake.ai).
It powers our Document Ingestion API, which processes millions of documents every month across a heterogeneous fleet of machines fully distributed, fully managed. Document processing was our testbed: OCR, layout detection, table extraction, entity recognition. Every document touches multiple models, multiple machines, multiple failure modes. If the infrastructure couldn't handle that, it couldn't handle anything.
But the compute stack itself is general purpose. It replaces the entire Kubernetes + Celery + Spark + Postgres stack with a single abstraction:
Write your workflow as if it runs on a single machine. In production, it gets transparently distributed across CPUs and GPUs, and scales to whatever the workload demands.
No queues to configure. No job schedulers to manage. No Spark clusters to provision. No glue code bridging systems that weren't designed to work together.
The key insight: use S3 as the backbone for durable execution instead of databases. AI workloads deal in unstructured data—documents, images, embeddings, model outputs. This data already lives in object storage. By building the execution engine around S3 rather than Postgres or Cassandra, we eliminated an entire class of serialization problems and made checkpointing nearly free.
GraphRAG on Tensorlake
Each step runs as an isolated function with its own compute requirements.
Step-level functions

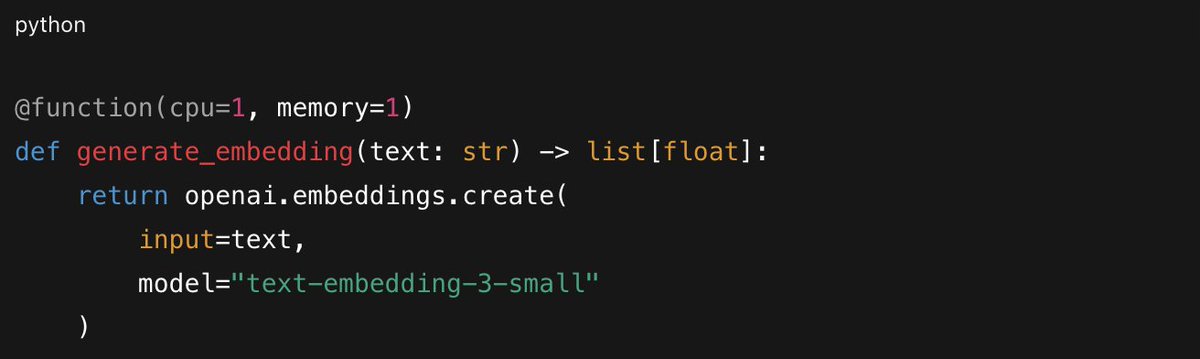
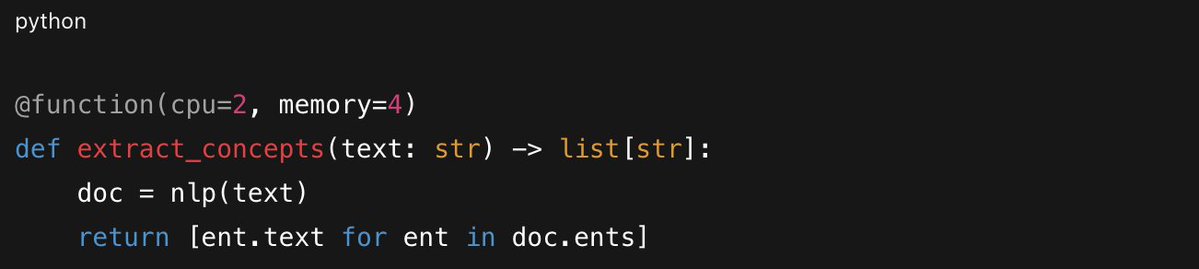
The magic is in `.map()`. Fan out to thousands of workers with one line:
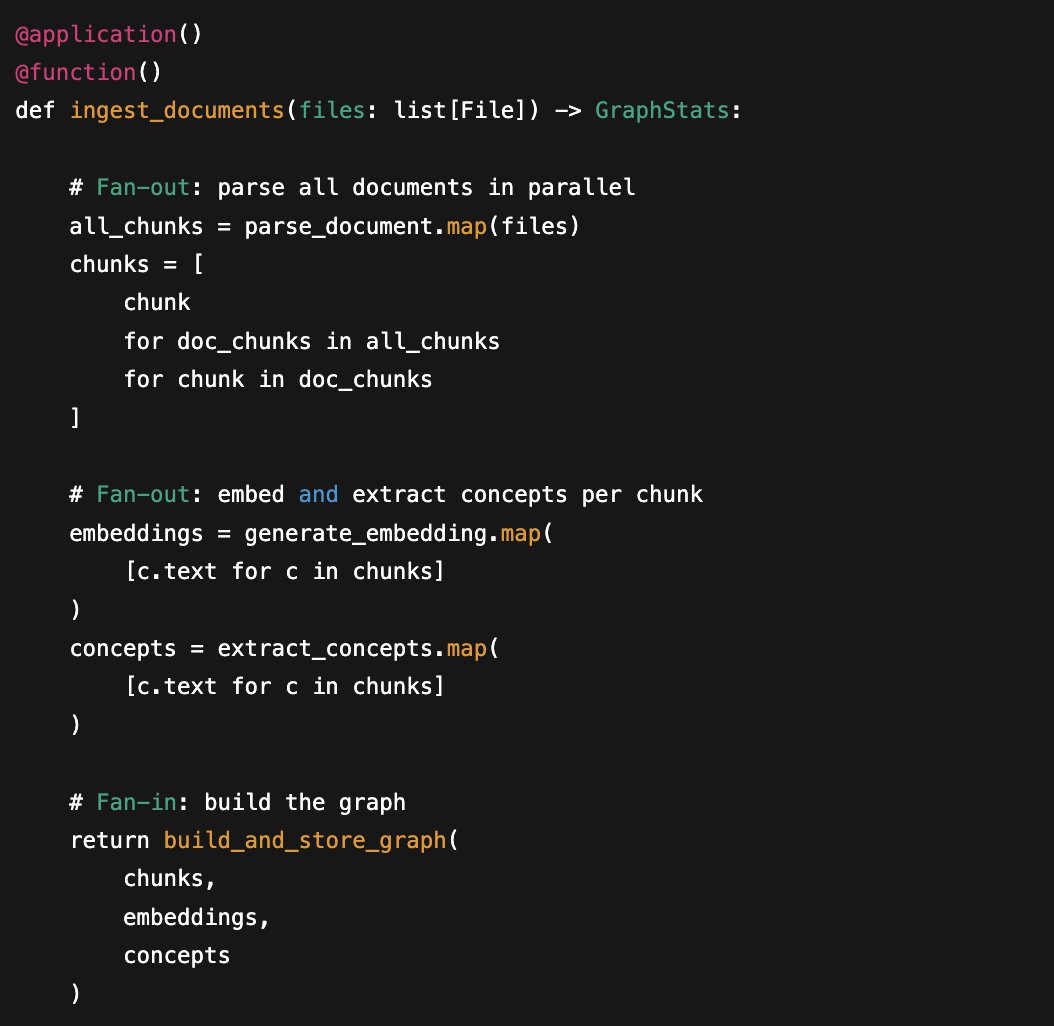
Execution Flow
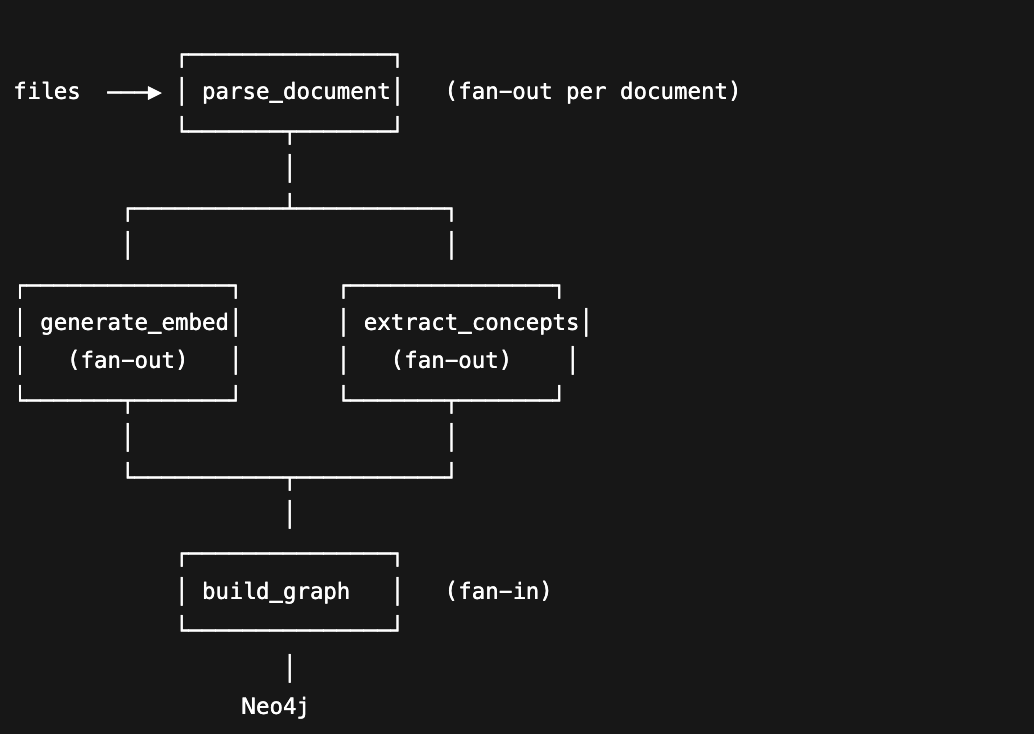
When a function fails, Tensorlake doesn't re-execute successful steps - it reads the checkpointed output from S3 and continues. If the pipeline dies at chunk 847, the retry resumes from the last checkpoint, not from zero.
This isn't a batch job you run manually, it's a live HTTP endpoint. Deploy once, and it's available on-demand whenever someone wants to add a document to the knowledge graph:
No documents in the queue? The system scales to zero. A thousand PDFs arrive at once? Tensorlake spins up workers to handle them in parallel. You're not paying for idle clusters or babysitting Spark jobs. The infrastructure responds to the workload, not the other way around.

The Results
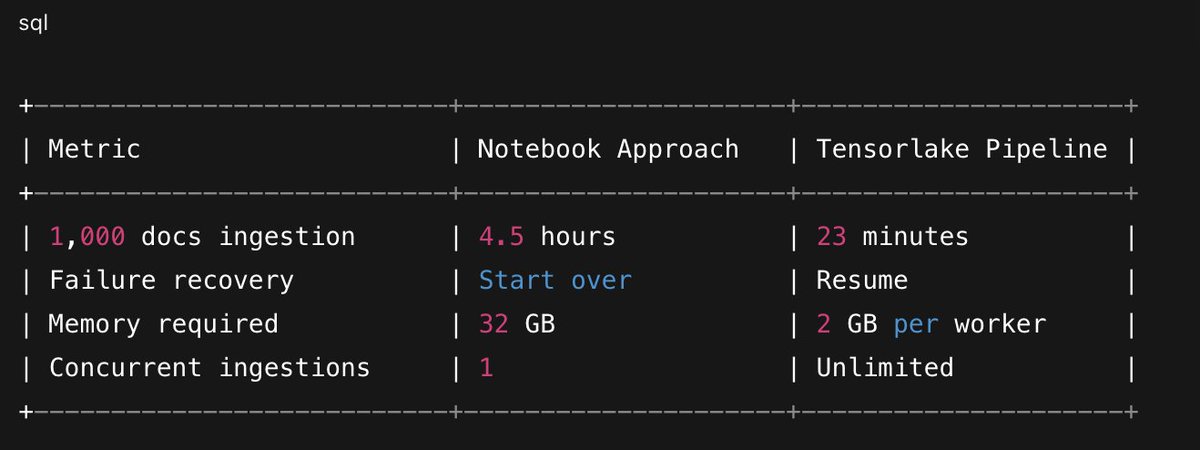
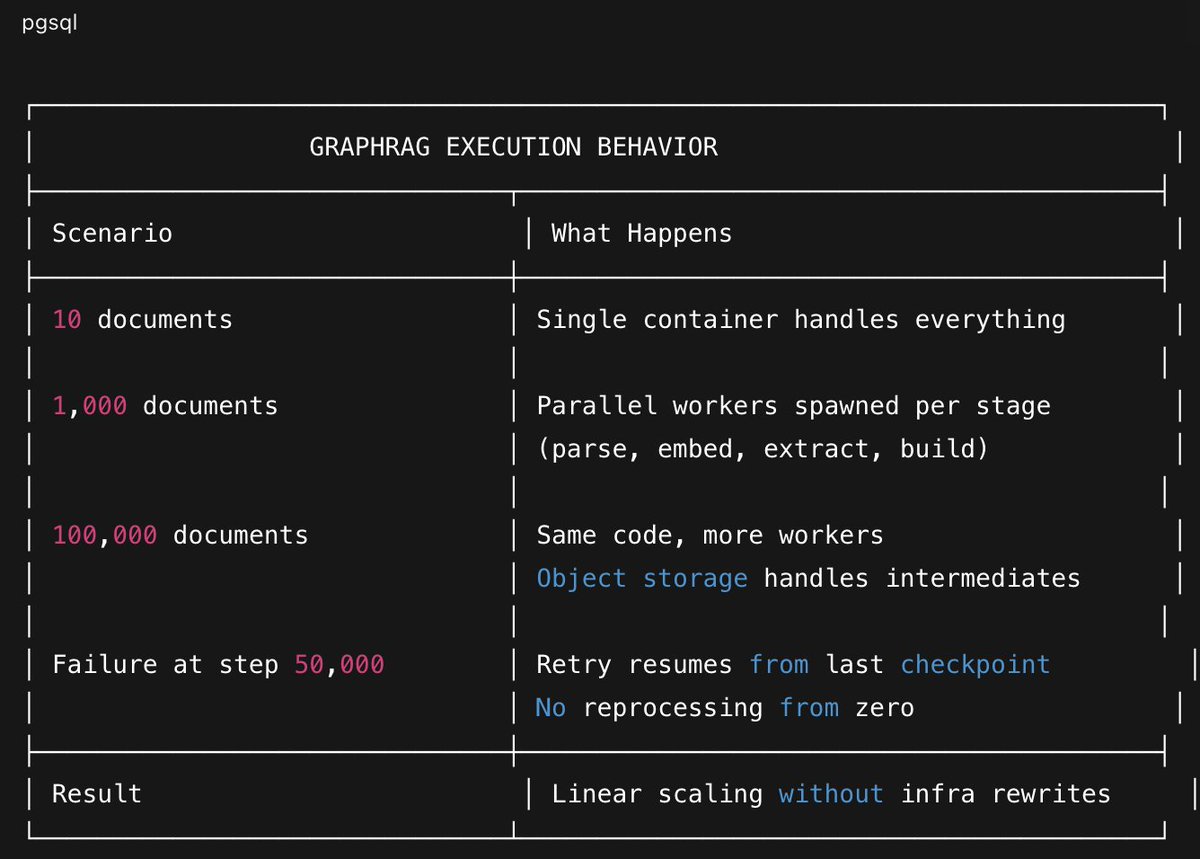
Try It
git clone https://github.com/tensorlakeai/examples/tree/main/graph-rag-pipeline
cd graph-rag-pipeline
tensorlake secrets set OPENAI_API_KEY <your-key>
tensorlake secrets set NEO4J_URI neo4j+s://xxx.databases.neo4j.io
tensorlake secrets set NEO4J_PASSWORD <password>
tensorlake deploy app.py
For a small proof of concept, a notebook is fine. For production GraphRAG with retries, scale, and real users, you need infrastructure that doesn’t become the bottleneck.
Built with Tensorlake(https://tensorlake.ai) and Neo4j(https://neo4j.com). See the GraphRAG paper(https://arxiv.org/abs/2404.16130) for the original algorithm.

Related articles

Get server-less runtime for agents and data ingestion

Tensorlake is the Agentic Compute Runtime the durable serverless platform that runs Agents at scale.
“With Tensorlake, we've been able to handle complex document parsing and data formats that many other providers don't support natively, at a throughput that significantly improves our application's UX. Beyond the technology, the team's responsiveness stands out, they quickly iterate on our feedback and continuously expand the model's capabilities.”
"At SIXT, we're building AI-powered experiences for millions of customers while managing the complexity of enterprise-scale data. TensorLake gives us the foundation we need—reliable document ingestion that runs securely in our VPC to power our generative AI initiatives."
“Tensorlake enabled us to avoid building and operating an in-house OCR pipeline by providing a robust, scalable OCR and document ingestion layer with excellent accuracy and feature coverage. Ongoing improvements to the platform, combined with strong technical support, make it a dependable foundation for our scientific document workflows.”
"For BindHQ customers, the integration with Tensorlake represents a shift from manual data handling to intelligent automation, helping insurance businesses operate with greater precision, and responsiveness across a variety of transactions"
“Tensorlake let us ship faster and stay reliable from day one. Complex stateful AI workloads that used to require serious infra engineering are now just long-running functions. As we scale, that means we can stay lean—building product, not managing infrastructure.”
