The harness can improve model performance
The result obtained by ForgeCode is the empirical version of something existing coding agents such as TongAgents demonstrated from the research side[^1] earlier this year 2026: wrapping the same Gemini 3.1 Pro model in a different orchestration layer moved it from 55% to 80.2% on the same benchmark — a +25 percentage point gain without changing the model. The framework is doing more work than the model in both cases.
The specific mechanisms behind ForgeCode's performance are simpler than you might expect. The most interesting is how it structures tool call schemas.
When an LLM needs to call a tool, it uses JSON describing which tool and with what arguments. If the schema it received was deeply nested or had unpredictable field ordering, the model makes more formatting errors. ForgeCode's execute_chat_turn() sends flattened schemas with consistent field order. Same model, differently structured prompt — fewer tool-call failures. The model did not improve its capabilities, but the harness is better at tool calling.
The parallel tool execution is the other piece worth noting. Most coding agents run tool calls sequentially: request a file read, wait, request the next one. ForgeCode uses join_all() to fire independent tool calls simultaneously. The claimed speedup is 3–5× on tasks that start with reading across multiple files.
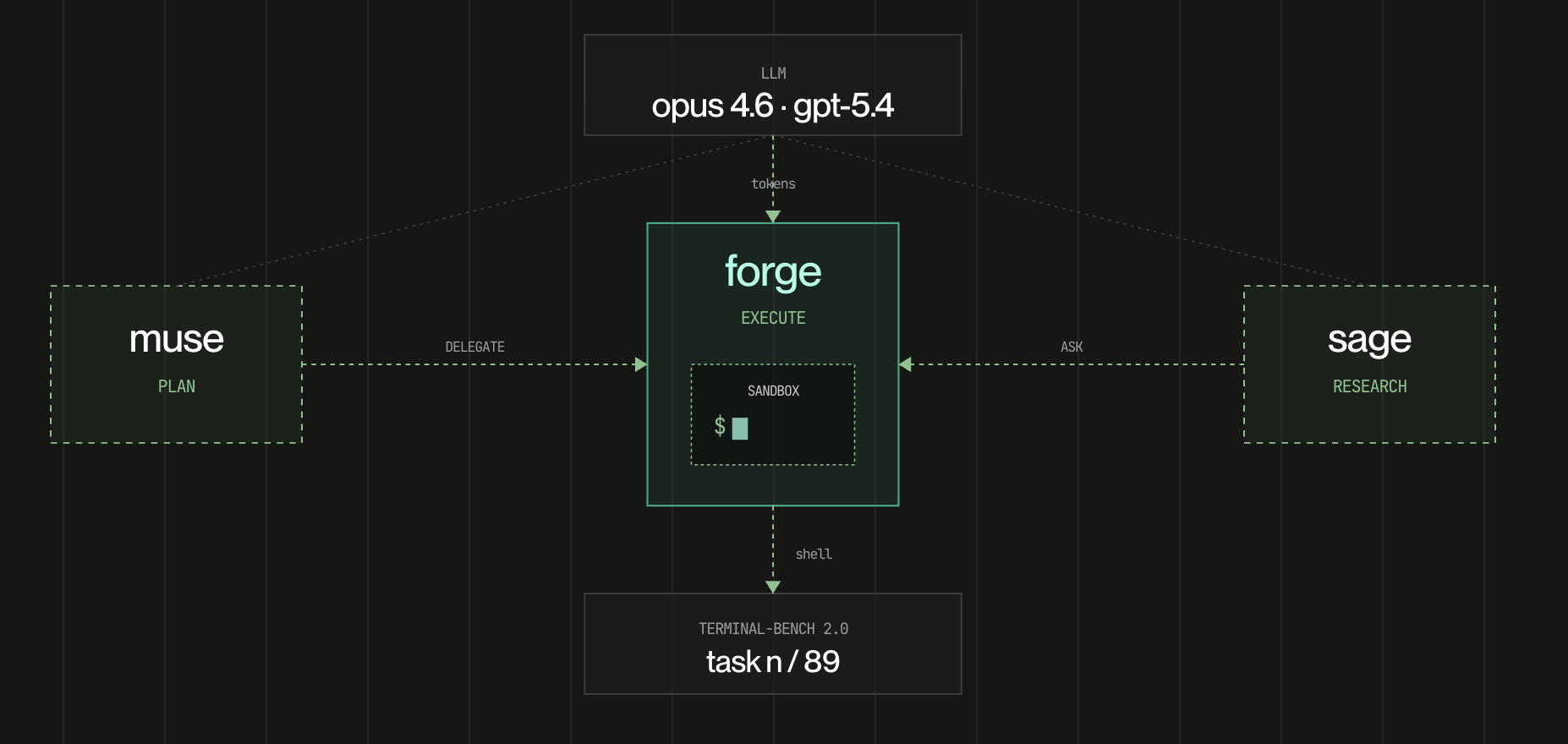
ForgeCode design
The three named agents — Forge for execution, Muse for planning, Sage for research — each get their own model, tool set, and isolated context window. This isn't a new concept, but the execution has some interesting properties: because sub-agent spawning goes through join_all(), a single orchestrator turn can spin up multiple Forge instances running in parallel on independent subtasks. And because sub-agents can themselves spawn sub-agents, the recursion continues until the task is completed rather than stopping at one level of delegation.
ForgeCode also mentions its current limitations: no persistent memory across sessions, no checkpoint or resume if the process dies mid-task, a smaller community than Cline or OpenCode.
The full Terminal-Bench 2.0 comparison is at terminal-bench.com.
ForgeCode can be set up at the new Tensorlake Harness site https://www.harness.new/.
[^1]: Zhang, Bofei, et al. "Tongui: Building generalized gui agents by learning from multimodal web tutorials." arXiv e-prints (2025): arXiv-2504.