I kept seeing people talk about Kimi K2.6, mostly because it looked like a strong coding model that did not cost Opus-level money.
It is open-weight, much cheaper than the usual premium coding models, and built around tool-heavy agentic workflows.
So I wanted to test it properly.
Not just by looking at benchmarks, but by putting it next to a model that we, or at least I, already trust a lot for coding. None other than Claude Opus 4.7.
Claude Opus 4.7 is the expensive closed frontier model. Kimi K2.6 is the cheaper open-weight model trying to get close enough for serious coding work.
And that is what makes this comparison interesting.
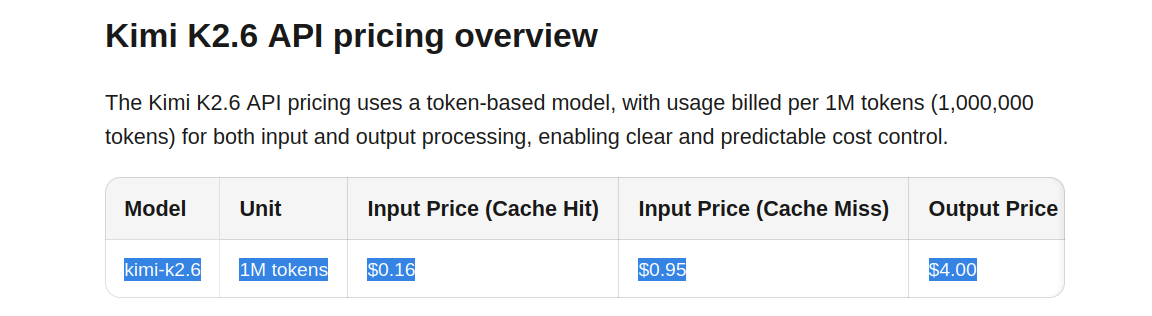
Claude Opus 4.7 costs $5 per 1M input tokens and $25 per 1M output tokens. Kimi K2.6 is listed at $0.95 per 1M input tokens, $4 per 1M output tokens, and $0.16 per 1M cached input tokens.
So yeah, the difference is pretty crazy.
For this post, I gave both models the same coding task and compared the output, cost, token usage, and how the overall experience felt.
TL;DR
If you want the quick take, Claude Opus 4.7 clearly won this test, and it was not really close.
- Claude Opus 4.7: Test 1 was smooth, and Test 2 was even better. It built the local fixer, added Tensorlake sandboxes, and even kept the old flow working. Super expensive, but it worked.
- Kimi K2.6: Much cheaper, but painful on this task. Test 1 missed the patched source view, and Test 2 failed even with Opus's working base. It used a lot of tokens and needed way too much babysitting.
If I had to pick one for real project work, I would still pick Opus 4.7. Kimi K2.6 is interesting because it is open-weight and cheap, but once the task gets a bit tough, it starts needing way too much babysitting.
Brief on Kimi K2.6
Before we jump into the coding test, let's also talk about Kimi K2.6, because this is probably one of the most interesting open-weight coding model releases right now.
Moonshot AI released Kimi K2.6 on April 20, 2026, as an open-weight agentic coding model built for long runs, tool use, autonomous execution, and multi-agent workflows.
The model itself is a 1T parameter Mixture-of-Experts model, with around 32B active parameters per token. The architecture is also basically the same as Kimi K2.5, so the K2.6 gains mostly seem to come from post-training and not a completely new base architecture.
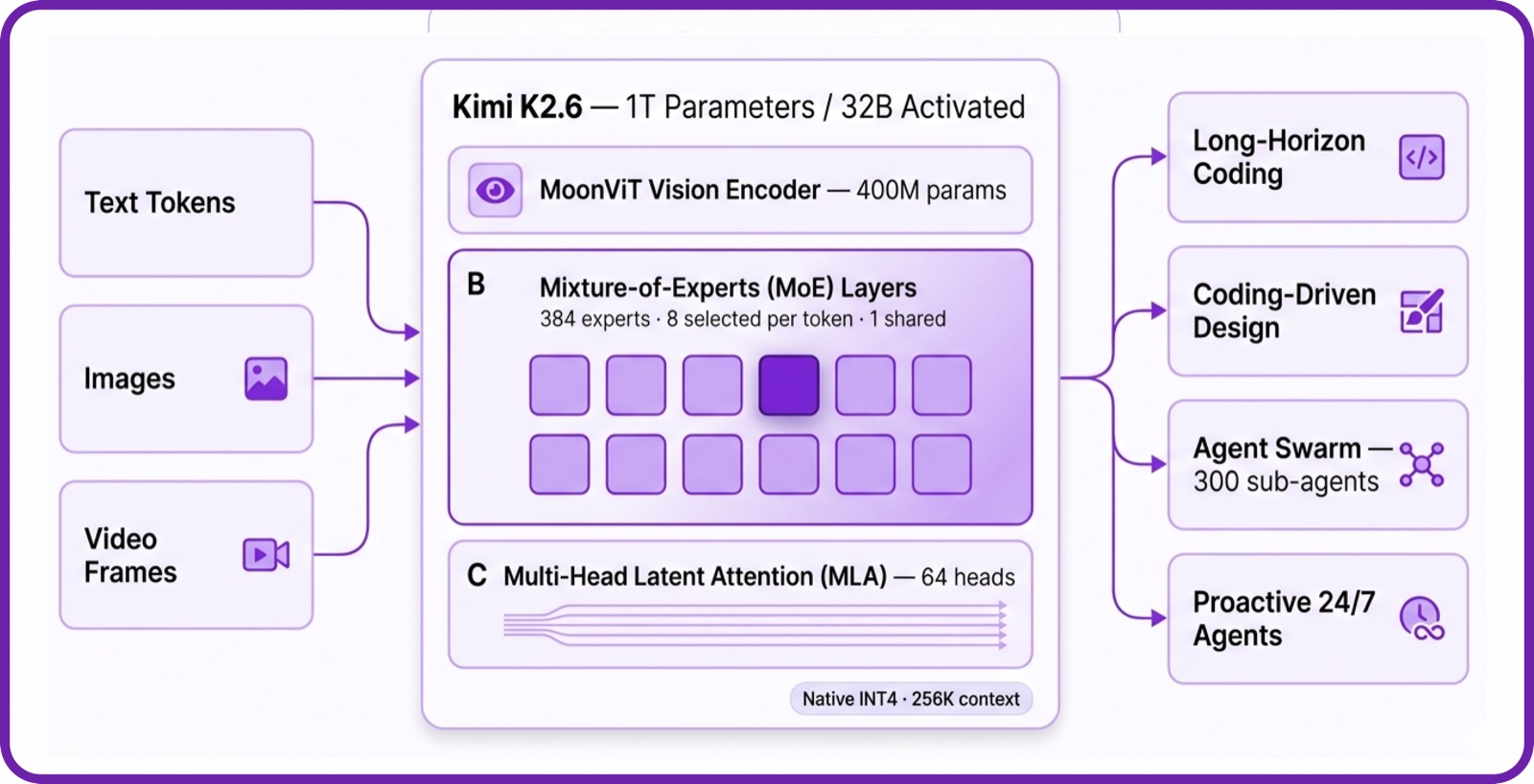
Kimi K2.6 supports a 262k token context window. It also supports native image input, and this release adds native video input through MoonViT. That is useful, as you can guess, like working with screenshots, Figma designs, and all that stuff.
Now comes the important bit: the coding benchmark.
On Moonshot's published numbers, Kimi K2.6 scores 58.6% on SWE-Bench Pro, 80.2% on SWE-Bench Verified, 66.7% on Terminal-Bench 2.0, and 89.6% on LiveCodeBench v6.
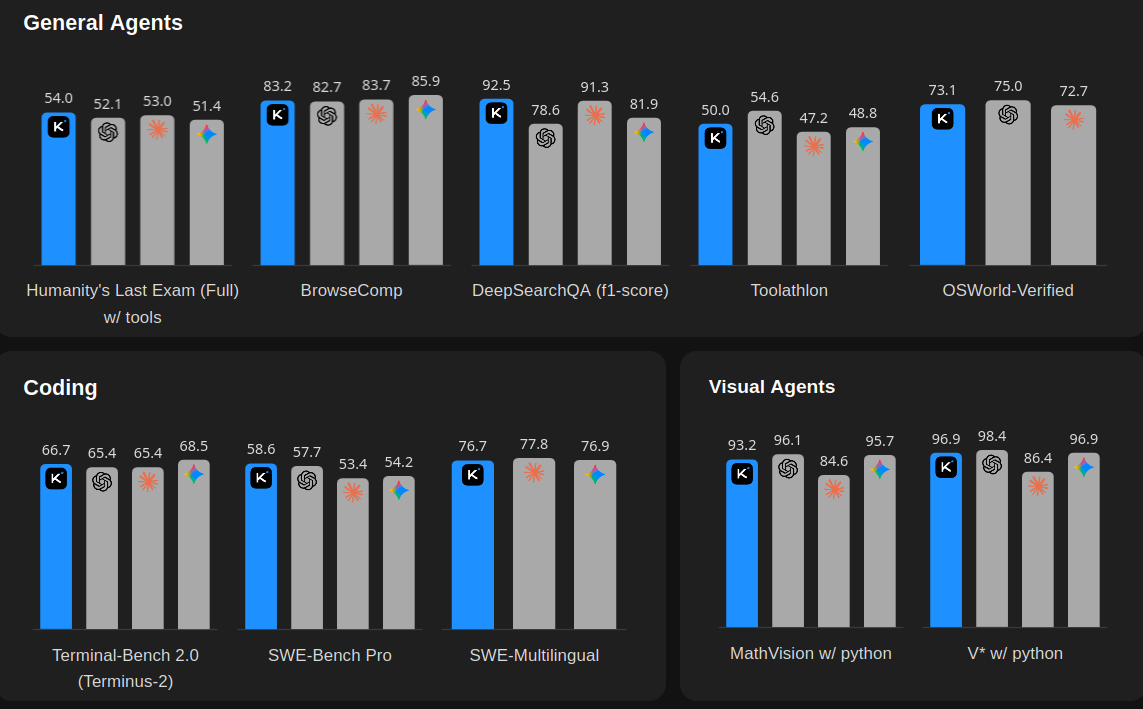
The SWE-Bench Pro number is the main one I care about here.
Kimi K2.6 scores 58.6%, compared to Claude Opus 4.6 at 53.4%. The numbers predate Opus 4.7, so I would not frame this as a direct benchmark win over Opus 4.7. But the point is still pretty simple: Kimi K2.6 is now in the same coding-model tier as Anthropic's top Opus line.
Which is a huge win for an open model, btw.
And the cost difference is big.
Claude Opus 4.7 is priced at $5 per 1M input tokens and $25 per 1M output tokens, according to Anthropic. Kimi K2.6's official Moonshot pricing is:
- $0.95 per 1M input tokens
- $0.16 per 1M cached input tokens
- $4.00 per 1M output tokens
That pricing is probably one of the biggest wins of Kimi K2.6.
Coding agents reuse a lot of context: repo summaries, system prompts, tool schemas, and previous state. So the $0.16 cached input price can make a real difference for longer sessions.
Self-hosting is not lightweight though. The native INT4 release is still around 595GB, so this is not a casual local model.
Against Claude Opus 4.7, the tradeoff is pretty clear.
Opus 4.7 is the premium closed model. Kimi K2.6 is the cheaper, open-weight, agentic coding option.
And for this test, that is exactly what I want to check: whether Kimi K2.6 can actually perform well in a real coding task, not just look good on the benchmark table.
Coding Comparison
For this test, I used the following CLI coding agents:
- Claude Opus 4.7: Claude Code, Anthropic's terminal-based agentic coding tool
- Kimi K2.6: OpenCode via OpenRouter
This is a practical coding test, so both models get the same prompt. I will compare time taken, code quality, token usage, cost, and all that stuff.
What are we building?
For this test, we are building a small AI Fix Runner.
A user picks a broken repo, runs the app, and the system tries to fix it. It runs the tests, applies a patch, reruns the tests, and shows the final result.
It's not as simple as it sounds.
The test has two parts.
First, both models build the local version. This gives us the base app: broken repos, repair loop, backend, UI, logs, and run history.
Then comes the real test.
We take that local runner and replace it with Tensorlake Sandboxes. Tensorlake provides isolated MicroVM sandboxes for running coding agents, builds, and tool calls, with filesystem and memory preserved across suspend/resume.
So, now the flow becomes:
Broken repo -> Tensorlake sandbox -> test fails -> patch applied -> test passesThat is where the comparison really matters. Can the model keep the app working and wire up Tensorlake properly, without breaking anything?
There are built-in broken repos so the app works right away. Users can also bring their own repo and run it through the same flow.
NOTE: Also, this is not a one-shot prompt test. I let both models debug, recover, and keep going like in a real coding workflow.
Test Prompts
Both models received the same prompts for each test.
- Test 1 Prompt: Local AI Fix Runner Prompt
- Test 2 Prompt: Tensorlake Sandbox Integration
Test 1: Local AI Fix Runner
This first test is the basic version of the idea.
Nothing super fancy here. It's supposed to build a local sandboxed environment for fixing bugs in the source code given by the user or the fixtures in place.
Claude Opus 4.7
Claude Opus 4.7 did really well on Test 1.
It built the local AI Fix Runner into a proper working app. The UI looked solid (too good than expected), the backend was clean, and the whole repair loop worked end to end.
The app came with all three broken fixture repos:
invoice-calculator-bugmarkdown-parser-bugtodo-api-bug
Each one could be run right away. The flow was exactly what I wanted: install dependencies, run tests, see the failure, apply a patch, rerun tests, and then run the build.
The UI was solid, but the best part was the API. I could test everything from the terminal without touching the frontend. More like a real service than a demo app.
First, check the server:
curl http://localhost:8787/healthThen list the fixtures:
curl http://localhost:8787/api/fixturesThen start a repair run:
curl -X POST http://localhost:8787/api/runs \
-H 'Content-Type: application/json' \
-d '{
"source": {"type":"fixture","fixtureId":"invoice-calculator-bug"},
"maxAttempts": 3,
"commands": {
"install": ["npm","install"],
"test": ["npm","test"],
"build": ["npm","run","build"]
},
"runBuildAfterTestsPass": true
}'After that, I could poll the run directly:
curl http://localhost:8787/api/runs/<RUN>And you can see the whole thing happen:
install -> test fails -> patch applied -> test passes -> build passesIt also added some safety checks. For example, if you try to sneak in something like rm -rf /, it rejects the request with a 400. Pretty important for a tool that runs repo commands locally.
curl -X POST http://localhost:8787/api/runs \
-H 'Content-Type: application/json' \
-d '{
"source":{"type":"fixture","fixtureId":"invoice-calculator-bug"},
"maxAttempts":3,
"commands":{
"install":["rm","-rf","/"],
"test":["npm","test"],
"build":["npm","run","build"]
},
"runBuildAfterTestsPass":true
}'There was one bug though.
Opus said it set KEEP_WORKSPACES=true, but the final workspace was not saved. The run showed up in the UI, but tmp/workspaces was empty.
In the next follow-up it fixed it cleanly. Turns out the backend was loading .env from the wrong place, so KEEP_WORKSPACES was still false.

You can find the code it generated here: Claude Opus 4.7 Code.
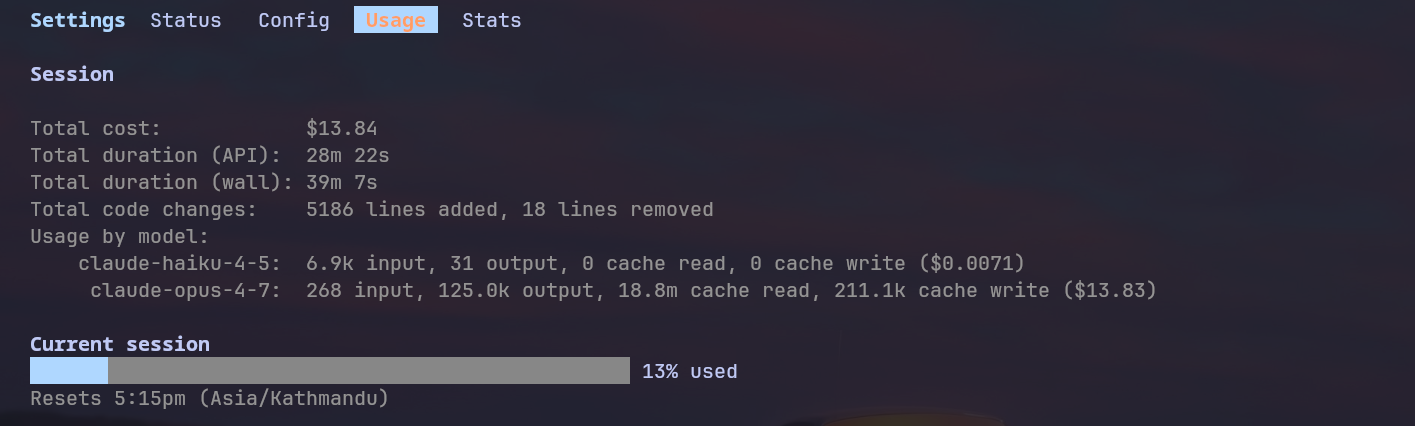
Run stats:
- Cost: $13.84
- Duration: 28min 22sec (API time), 39min 7sec (wall time)
- Code Changes: +5,186 lines, -18 lines
- Token Usage:
- Claude Haiku 4.5: 6.9k input, 31 output
- Claude Opus 4.7: 268 input, 125.0k output
- Cache read: 18.8M
- Cache write: 211.1k
Quick Verdict
Opus passed Test 1 pretty easily.
The cost turned out a bit painful, as it's an expensive model, and it also had to write three different failing projects.
Other than one small bug, everything else was smooth.
Really strong first run.
Kimi K2.6
Kimi K2.6 was rough in Test 1.
And I mean really rough.
The run started around 1:35 PM and finished around 3:14 PM. So almost 1 hour 40 minutes for one run.
For context, this was only the local version.
The painful part is that after all that time, the implementation still did not really come together.
The whole idea of this app is simple: run a broken repo, patch it, rerun the tests, and show the fixed source code.
But Kimi missed that core piece. It did not have any way to view the patched source code, which basically kills the entire point of the project.

It did expose API endpoints though, so I could at least test parts of the flow from the terminal.
Start the server:
npm run dev:apiList the fixtures:
curl http://localhost:8787/api/fixturesStart a repair run:
curl -X POST http://localhost:8787/api/runs \
-H "Content-Type: application/json" \
-d '{
"source": {"type": "fixture", "fixtureId": "invoice-calculator-bug"},
"maxAttempts": 3,
"commands": {
"install": ["npm", "install"],
"test": ["npm", "test"],
"build": ["npm", "run", "build"]
},
"runBuildAfterTestsPass": true
}'So yeah, the backend had the right idea. But if I cannot inspect the patched source code, the repair loop is not very useful.
That was pretty disappointing, especially because Kimi K2.6 is supposed to be strong at coding and long agent-style workflows.
The cost also surprised me.
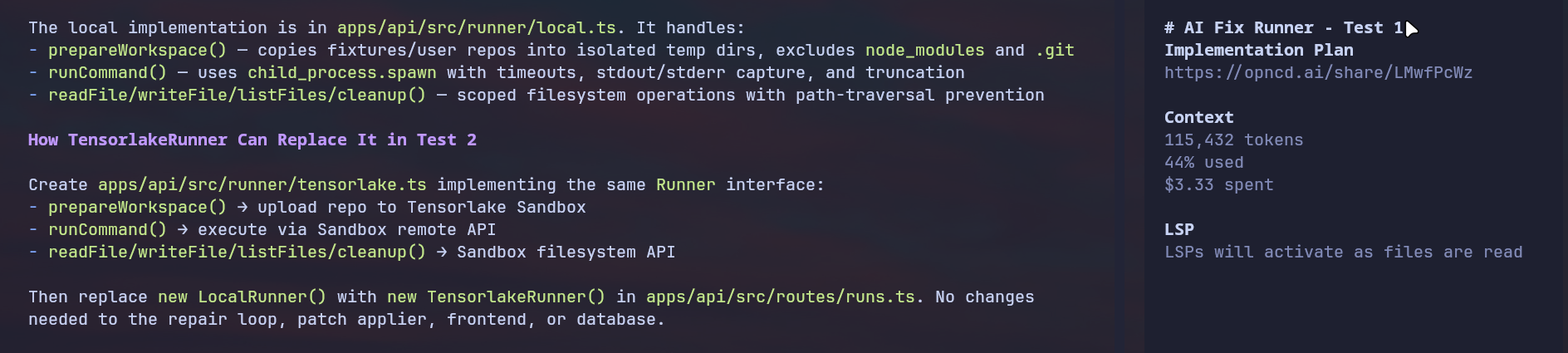
This is supposed to be the cheaper model, but this one run still crossed 115k+ tokens, cost around $3.40, and used 44% of the whole session.
For a failed local run, that is just not justified.
But still, compared to Opus 4.7, it did this at almost 1/4th the price.
With a few bugs, maybe that is still fine. That is probably the only way I can take this positively.
You can find the code it generated here: Kimi K2.6 Code.
Run stats:
- Cost: ~$3.40
- Duration: ~1hr 39min wall time
- Token Usage: 115k+
- Session Usage: 44%
- Result: failed to produce a clean working app
Quick Verdict
Kimi K2.6 failed Test 1 for me.
It took way too long, spent most of the time fixing its own errors, and still missed the main point of the project.
Super disappointing run.
Test 2: Tensorlake Sandbox Integration
Now this is where the actual test begins.
The local fixer is ready, so now it is time to replace the local runner with Tensorlake Sandboxes.
The idea is simple. Instead of running broken repos on my machine, the app should spin up an isolated Tensorlake MicroVM, copy the repo there, run the tests, apply the patch, and prove the fix inside the sandbox.
Claude Opus 4.7
Claude Opus 4.7 absolutely nailed Test 2.
This was the real Tensorlake test. The local runner was already done, so now the job was to replace it with a real Tensorlake sandbox flow.
And, it worked like a charm.
The app now spins up a temporary Tensorlake sandbox, copies the repo into it, runs the install/test/build flow, applies the patch, verifies the fix, and then disposes the sandbox after execution. That is exactly what I wanted.
It did spend a good amount of time planning. But after that, the implementation was quick. I barely had to ask for changes. I only had to fill in the Tensorlake envs and add a few new config values.
The verification flow was also clean:
npm install
npm test
npm run buildAnd for Tensorlake:
export TENSORLAKE_API_KEY=tl_apiKey_...
npm run dev
curl http://localhost:8787/api/config
npm run test:tensorlake:liveThe local regression still passed too, so it did not break the Test 1 implementation while adding Tensorlake.
You can find the code it generated here: Claude Opus 4.7 Code - Tensorlake.
Run stats:
- Cost: ~$24.39
- Duration: 23min 26sec
- Code Changes: +2,067 lines, -448 lines
- Token Usage:
- Claude Haiku 4.5: 18.7k input, ~25.9k output, 1.2M cache read, 299.9k cache write
- Claude Opus 4.7: ~6.5k input, 156.7k output, 30.3M cache read, 743.8k cache write
Quick Verdict
Opus crushed the Tensorlake integration.
It kept the local runner working, added the sandbox runner cleanly, and handled the temporary sandbox lifecycle exactly how I wanted.
Opus models are crazy once you start using them in a real project. That is when you realize how powerful these things are.
Anthropic really cooks when it comes to coding models.
Kimi K2.6
Since the last Kimi build turned out completely weird, I decided to base this test on the Opus Test 1 implementation.
So basically, both models were now building on top of the same base Opus commit.
But again, after almost an hour of back and forth, and after spending over 150k tokens, I got the same result.

The model simply failed to make meaningful progress. I am not sure if OpenRouter was the issue here, or if the model itself just cannot handle this kind of real-world task.
At this point, I honestly do not see why this model is getting so much hype.
NOTE: I already did a similar test with Kimi K2.6 earlier, which you can find here, and the result was pretty much the same. As soon as the task gets a little tough, the model just gives up.
Conclusion
Both Claude Opus 4.7 and Kimi K2.6 were pretty solid in this test.
Plus, the idea itself was not that common. This was not really a one-shot thing, so props to both models.
Opus 4.7 was the stronger one for me overall. The output felt cleaner, more organized, and easier to build on. That is usually where Anthropic models shine.
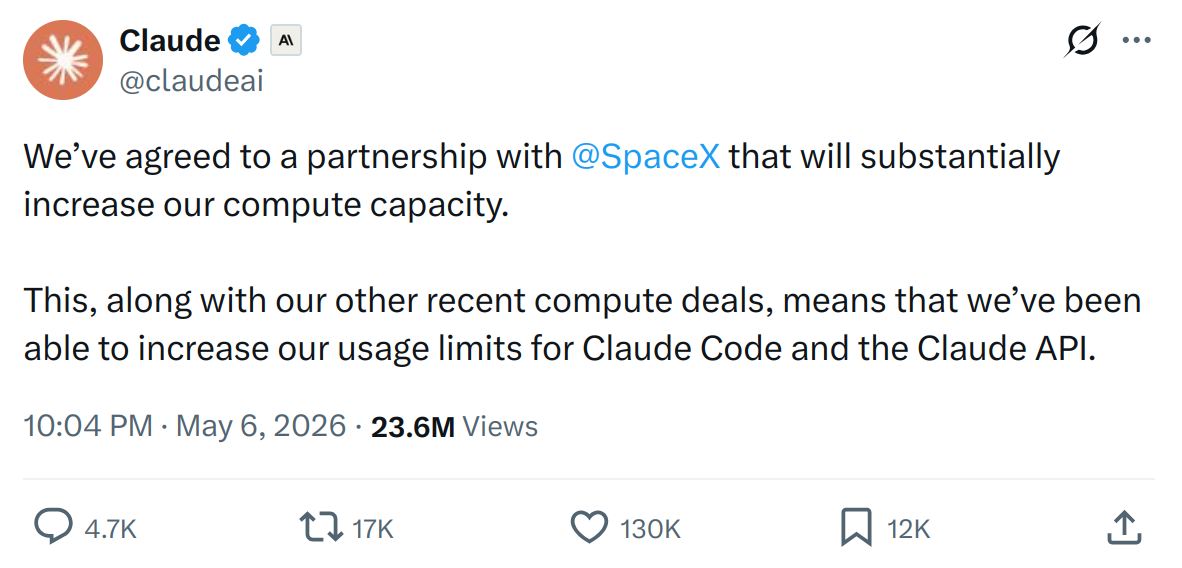
Previously, for this kind of task, the session limit would have been a real pain.
But after Anthropic's May update with the SpaceX compute partnership, that part seems a bit better now. Claude Code limits were reportedly increased, so at least this is not as painful as it used to be.
And honestly, this also makes me more excited for whatever comes next from Anthropic.
These Claude models are already damn good at coding. And now there are all these reports around Claude Mythos, which seems like the next jump in Claude's capability stack.
What's wild is that it is reportedly finding serious security bugs in real software. Anthropic's own red-team post says Mythos Preview found working exploits, which is nuts.
So yeah, whatever Claude 5 turns into, I am very curious.
These models already feel crazy good at coding. If Mythos is any hint of what comes next, it might break a lot of our current theories around AI model intelligence.
Kimi K2.6 is interesting for a different reason. It is open-weight, cheaper to run, and built around coding. How cool is that?
You get such a decent open model, and you can possibly run it locally?
Open models have not always been my first choice for real projects, but they are getting better with every release.
Kimi K2.6 is not ahead of Opus 4.7 for me yet, but it is close enough that I want to keep testing it.
Let's see where Kimi K2.6 goes from here.